Origami AI — a roadmap

Recent rise of text-to-image AI models such as Dall-E, Craiyon, Imagen, Stable Diffusion, and Midjourney, has spurred interest in the origami community. Some people, including myself, have experimented with generating images of origami models using these systems. While I was working on this text, ChatGPT got released, a model which works on text rather than images, but which despite certain shortcomings shows the potential Artificial Intelligence offers. On the other hand, such systems raise concerns, both related to the results they generate and to the way they make use of data scraped from the internet, and these concerns have been voiced within the origami community as well.
In this article, I present a roadmap for applying AI to the field of origami. Starting from what is possible today, I suggest how existing building blocks could be used and extended to bring us to a point where systems can design origami automatically based on user input. This is both a prediction of where things might go and a to-do list. While I focus on the technical aspects of the issue, and make the implicit assumption that having computers design origami is something we actually want, I couldn’t completely skip discussing the implications such systems might have for origami creators or the controversies such systems may cause. I also mention why certain tools, albeit technically feasible, might not materialize any time soon.
What “designed by AI” means
What does it mean for an origami model to be designed by AI? The AI should do exactly the same thing we require from a human designer: either to physically fold the model or to create a description that allows someone else to do it. Designing origami models without ever folding them is absolutely possible: I make full folds of only a small fraction of my designs. Since any kind of folding machine controlled by the AI would need to receive the model’s definition in one form or another anyway, we can skip the folding step and concentrate on the “providing a description“ step.
Recently, I stumbled upon some posts captioned as origami “designed by artificial intelligence“. I find such wording confusing since these are not models designed by AI. They are images of objects in origami style, which often boils down to their main features being triangulated, and at best to them bearing superficial similarity to images of origami models. While interesting and impressive, such images do not constitute origami designs: definitions that could be executed. Later posts by the same author mostly use more balanced descriptions.
Human designers can document their designs in multiple ways: by providing step-by-step drawings of the folding process, photo- or video-tutorials, or by drawing crease patterns (CP). Crease Patterns are not the easiest to use, but since they are easiest to describe mathematically, and they define a model in an almost unambiguous manner, they are the tool of choice for most computer software related to origami. CPs have their limitations, but they are powerful enough to handle most of the interesting cases. Therefore, I think we should accept a model as “designed by AI” if the AI generates an actually foldable crease pattern based on simple input such as a text prompt (e.g.: “deer with large antlers”). Other inputs and outputs might do as well, but given the usefulness of this approach and earlier developments in both AI and computational origami, I expect text-to-crease-pattern to be the first user interface for AI origami design.
Where we are now
As of today, generative text-to-image AI systems can create decent-looking images of origami-like models and very convincing images of specific models found in their training sets (sometimes limited to the paper boat and traditional crane). Larger, commercial systems are usually better at this than smaller, freely-available ones, e.g. Dall-E 2 vs Craiyon (formerly Dall-E Mini). However, progress is very quick and new AI models sometimes surpass their predecessors within weeks.
One important property of such AI systems is that their performance at specific tasks heavily depends upon the data sets used to train them. Such systems can often very well imitate art styles such as “oil painting” and subjects such as “mountain hut” or “forest”, which are widely represented in their training sets, but are not very good at origami since origami is not a very common subject in their training data.
However, this can be easily fixed. Using projects such as DreamBooth on Stable Diffusion, one can add data about new objects to an already existing AI model. I haven’t had the time to try it out, but I’m quite sure that adding a number of images of actual origami models to the AI model this way would improve its performance at origami-themed prompts. Also, the quality of origami-themed images improves with newer models even without any customization, probably due to larger training sets. Among the models I’ve tested, Dall-E 2 seems to generate most convincing images of origami models while those made by Midjourney have an easily recognizable style, which however resembles actual origami models less.
Inspiration generator

How far can this get us? Regardless of how good the AI system of this type is, it works only on images. This means it does not have any internal notion of the origami model being folded from paper and the limitations this forces upon the model’s structure. Nonetheless, with enough training data, and some prompt tuning, such models can even today generate images of origami models which would take even origami folders a while to figure out whether they represent actual models or just origami-styled pictures.
Unless the model contains clear giveaways of not being folded, it is not always so easy to determine whether it represents actual origami. Take for example the discussion I had with some origamists in social media about an origami-style elephant used as a company logo. The elephant was just a drawing made by a human with no origami experience, based on inspiration from actual origami models found online. And then, one participant of the discussion designed an origami model that looked like the drawing. So, the elephant was actually foldable even though the (human) designer was not aware of this. The same can happen to origami-style images generated by AI.
While this is not origami design per my previous definition yet, such an approach can bring us a bit closer to our goal. And lo and behold, while I was working on this text, I noticed this was already happening: there was a challenge posed by Grant Marshall (@FearlessFlourish) to fold in real life a model based on an AI-generated image, and someone succeeded in doing so. Unfortunately, while the experiment itself is praiseworthy, its description uses the over-hyped wording I criticized above, claiming the AI had already designed the model (why do we need to challenge human designers then?).
I call the stage described above,the inspiration generator stage. What the AI generates is an origami-style image which a human creator can use as inspiration for designing an actual origami model. If the model produces very lifelike images, they might be possible to reproduce in origami with high fidelity, as was the case with the human-drawn elephant. However, even not very good images could be inspiring, in the same way an origami creator can be inspired by a painting or by an interesting-looking rock: the inspiration has nothing to do with origami but may just open up some ideas in the beholder’s mind.
Working with CPs rather than folded models

Another experiment we could run even today would be feeding an AI model with pictures of actual origami crease patterns and checking out what it could generate based on such a training set. By default, the models I’ve tested have absolutely no idea what an origami crease pattern is, so this data would have to be added on as a customization. Even though we would still be working in image space, the AI model might figure out some features of CPs that make them foldable (since we would only use foldable CPs in training data) and reproduce them in generated images. While this is speculation, I wouldn’t be very surprised if even today’s models could — with enough training — generate proper flat-foldable CPs most of the time without being explicitly taught Maekawa’s theorem and other rules of flat-foldability, à la AlphaGo Zero.
Less likely, but still possible in my opinion, they might to some degree be able to generate crease patterns of models with specific topics since a CP’s symmetry depends on the number of appendages of the finished model. Such general symmetries make it possible to tell apart a CP of a four-legged animal from a CP of a spider without having to be able to read and create CPs in the general case. This task could further be simplified by limiting the experiment (and training set) to CPs using just a single technique, for example box pleating.
On the other hand, the AI model being able to consistently generate correct CPs which would fold into convincing models of specific animals, e.g. a dog that would clearly be different from a cat, is a different story altogether, and most probably not achievable by current AI models.
While the idea of working on images alone, without any reference to the rules of paperfolding, may sound extreme, such approaches sometimes do work. There have been experiments in weather forecasting based just on satellite images, without any reference to the underlying behavior of air masses and clouds. Another successful experiment was teaching an AI system to play computer games based only on images of what was visible on screen, without any explicit knowledge about the rules of those games. As most AI systems, such approaches rely on huge training sets and this may prove problematic in the case of origami.
Where we are going
Now, let’s fast-forward and imagine what a perfect, AI-driven origami design tool could look like, skipping for the moment the hard parts of how to get there. Here’s how I imagine a sample session:
> a deer with large antlers
[a folded model representing a realistic deer with large antlers appears in the 3D view, with the CP (e.g. 22.5°) in a side panel ]
> box pleating
[a new CP, this time using box pleating, and corresponding rendered folded model are generated]
> cartoon style
[proportions are changed to make the deer look more like Bambi]
> add eyes
[previous model had a smooth face, now a new version appears in which eyes are clearly marked by folds]
> longer legs
[modified model appears]
…
[user is satisfied with the design, switches to shaping mode]
> lift front left leg up
[change is applied to 3D view, CP remains same since it’s just shaping]
[user grabs the ears in 3D view and moves them around as if shaping an actual paper model]
[user can export the CP as well as 3D view, both in drawing and photorealistic style]
[user can generate drawings of step-by-step folding instructions for the model automatically]
This advanced tool should be able to perform all steps of design, meaning that its input should be just a rough description of the model, similar to what a client would provide to a human origami designer they hire. Current experience with image generation and ChatGPT suggests that text prompts could be the right choice: they are quite expressive, compact, and easily shared and discussed. Since for any input there are an infinite number of possible solutions, all as good as any other, it should be possible to manually set the random seed, and probably also additional settings controlling the algorithm’s behavior like those we see in current image generation models.

The system would also need to be interactive, with the possibility to easily modify the prompt or add changes or constraints while viewing their impact in real time. The dialogue-based approach demonstrated by ChatGPT seems to be the right tool for such gradual refinement. Some commonly used options, such as choosing box pleating over 22.5° method could become buttons in order to reduce typing. Some changes are easier to show than to describe, so the interface should also offer a 3D view allowing the collapse of the CP to be analyzed and minor manual changes to be introduced. This view could also allow shaping options, both suggested by the program and applied manually by the user, to be explored. Finally, there should probably also be a traditional CP editor with folding simulator for applying manual modifications at CP level.
Apart from being able to manually alter the CP or pose the model, the human creator’s role is about creating the right sequence of prompts to guide the design process until the model has desired characteristics, and finally folding the model in paper. I would not be surprised if physically folding models stayed out of reach of machines for longer time than designing them. Folding requires specialized hardware, driving the cost up, and there is less potential for reusing off-the-shelf components than in the case of software. Interestingly, even in the most extreme case where we get rid of interactivity and just let the human provide a single input prompt, leaving everything else to the AI, it remains the human’s role to initiate the design process, and to accept or reject what the AI generates.
How to get there
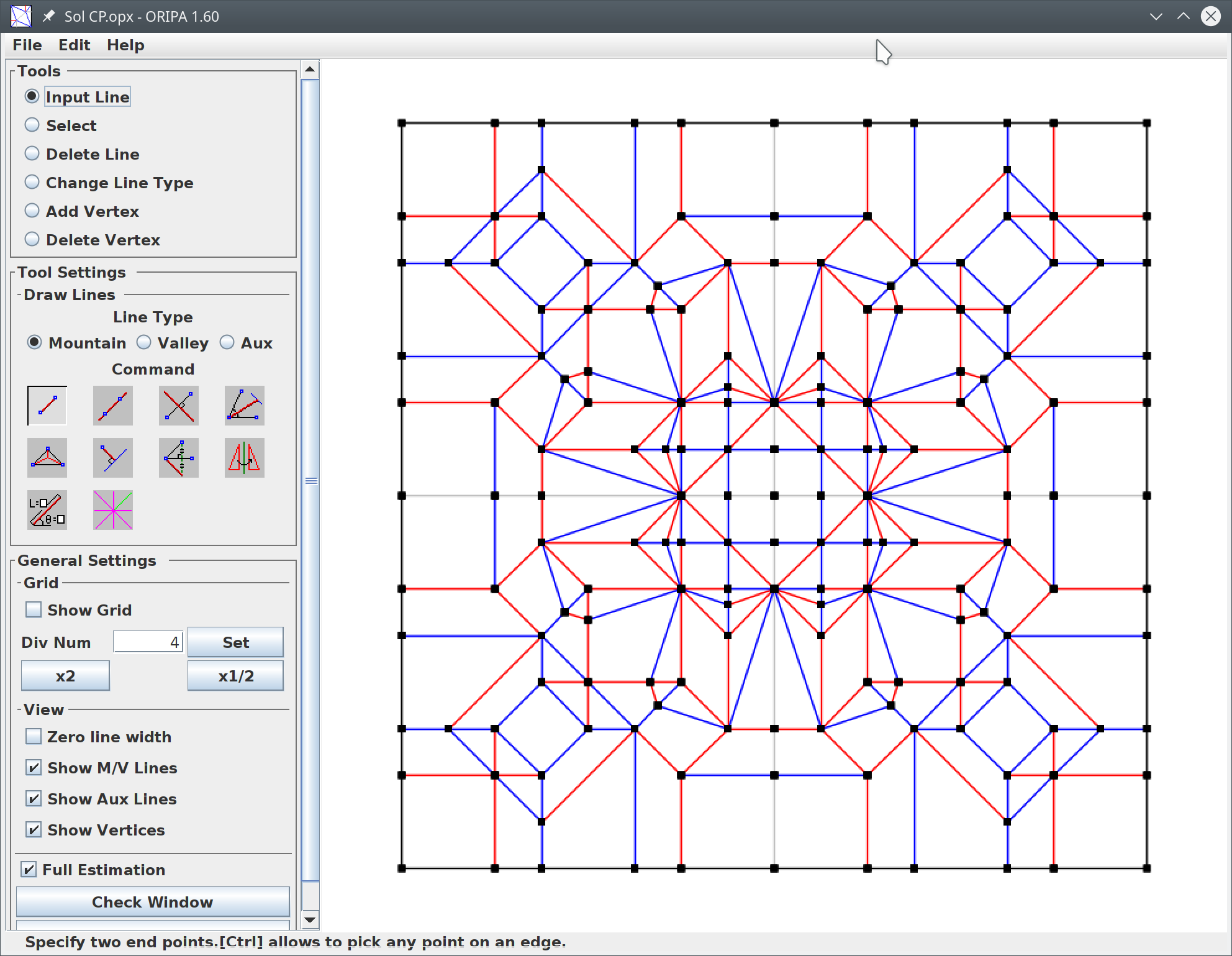
Before we delve into building the perfect system described above, let’s reflect on what we already have. Surprisingly, quite a few elements of the system are already in place, and work well without any AI, based only on strict algorithms. We have TreeMaker and Box Pleating Studio which receive a stick drawing of the model (e.g. a human or animal figure) as input and generate a crease pattern to fold it; Oripa and others which allow you to draw a crease pattern, check it for correctness, and have the program fold it for you on the screen; and Origami Simulator which allows you to virtually fold a crease pattern, and see how it interacts when you grab and pull parts of it with your mouse.
These subsystems are quite impressive on their own, but applying some AI in the right places could further improve them. Some of these changes could improve the performance of existing features while others could introduce completely new usage modes.
The bare minimum
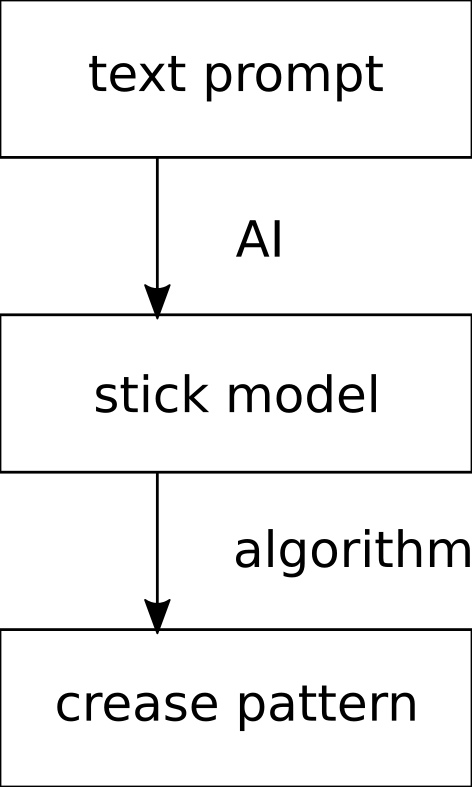
I think only one element currently missing is strictly necessary for a system to design origami according to my definition: the text-to-CP mapper. Given that we can already do stick-model-to-CP (without any AI), we just need to implement the missing text-to-stick-model step which does not sound that crazy given current generative models’ abilities. I guess that if fed with enough data (but on a scale which is actually practical to prepare), these existing models could become pretty good at generating convincing stick drawings from prompts such as “deer with big antlers”. One issue that would need to be taken care of is that these models generate bitmap images while we need vector drawings, but bitmap-to-vector works decently without any AI, and since stick drawings are a specific subclass of the general problem, it should be possible to fine-tune it to work even better.
The output from such a system would be crude (just a CP of the origami base, without the shaping usually necessary to make a model look like a real animal), but I would be willing to accept it as “origami designed by AI”.
Further improvements
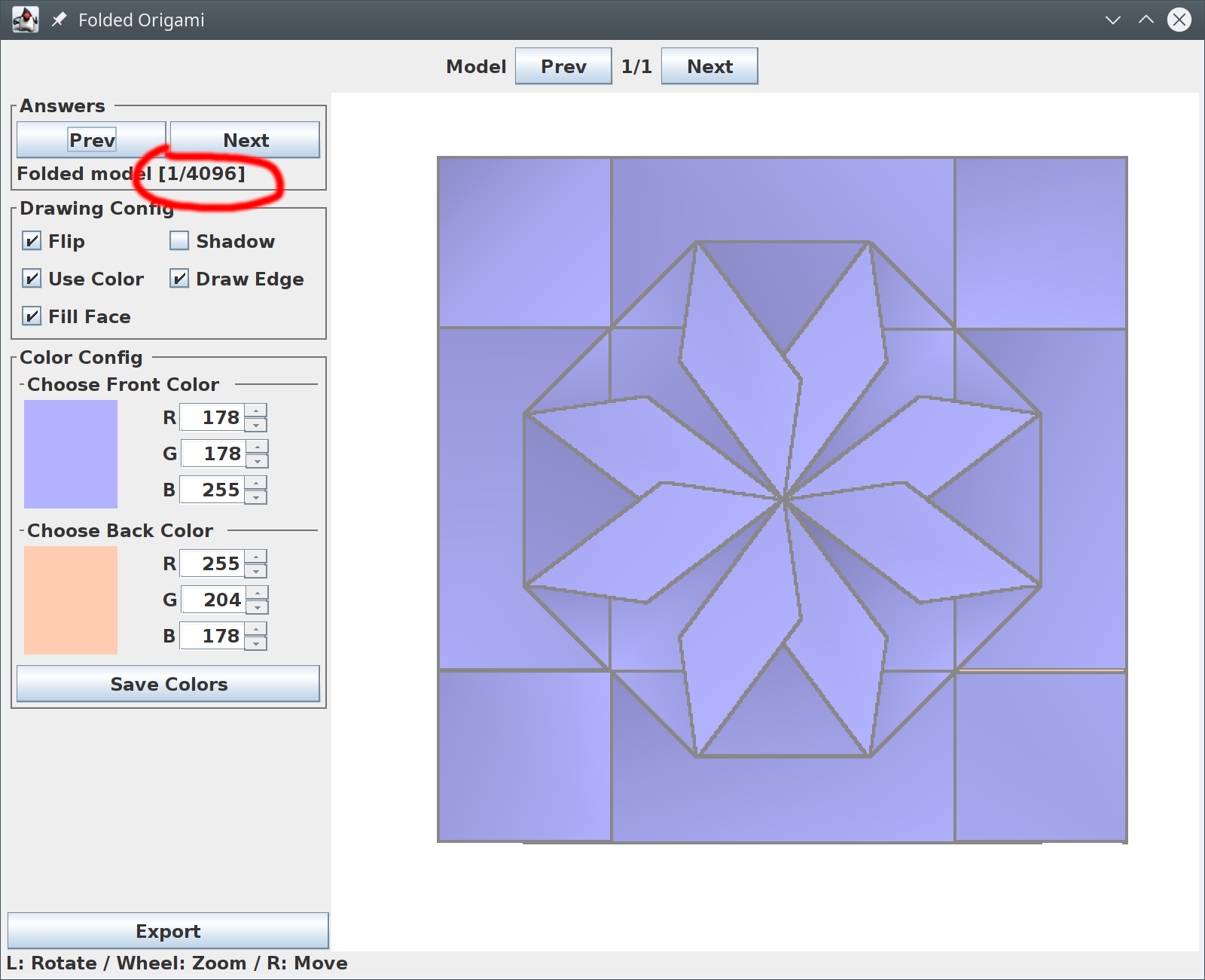
The improvements listed below could augment the basic AI-driven origami design system from previous paragraph, but many could be implemented independently of it, as extensions to existing, algorithm-based tools.
- Support for color change and other design features
- Support for multiple design paradigms (e.g. tree method, box pleating, hex pleating, non-flat-foldable designs, surface of revolution with curved folds, etc.)
- Style transfer
- Simulation of posing and shaping with “soft” deformations, both guided and automatic
- Automatically generating model descriptions or folding instructions in various formats: crease patterns, step by step instructions, maybe even video tutorials; this mechanism could be used both for models generated by the AI and for models designed by humans, which often remain relatively little known due to the effort required for diagramming them
- Generating folding instructions based on a video recording of a person folding the model rather than starting from a CP
- Based on pictures of step-by-step instructions, virtually folding the model and finding its CP; virtually folding a model based on a picture of its CP taken with a phone should be feasible already (image vectorization + algorithm-based CP folding)
- Reverse-engineering models based on pictures of the folded model
- Applying AI-based information retrieval to origami, for example finding a model’s name, author, and publication details based on a picture or a textual description (pretty much what Spot the Creator FB group does thanks to human helpers). This might already be possible to some degree if we trained a model such as ChatGPT on appropriate data.
- Automatically finding the layer orderings which make sense from a design perspective: some designs have lots of possible layer orderings which currently take lots of resources to generate and are hard to navigate in software
- Improving the performance of NP-hard or otherwise computationally intensive tasks such as determining whether a CP is flat-foldable, determining rigid foldability, etc. Heuristics do exist, but AI might deliver better results, faster.
Apart from that, the AI models would certainly be improved over time to generate better and better outputs for the same inputs, and to do it faster and faster. Since no system is perfect, over time some kind of prompt engineering would certainly be developed to help designers make more effective use of these tools.
Short-term roadmap for research into origami AI
We are currently at the inspiration generator stage. Some of the more advanced uses of AI for origami outlined above will be difficult to implement, but some might be relatively easy. Listed below are some developments I believe we should focus on right now, both in hope of achieving new results directly and for the purpose of paving the way for further research.
- Fine-tuning existing text-to-image models on large collections of origami model pictures in order to achieve better performance at the inspiration generator stage.
- Research into the inspiration generator approach: having humans design origami models based on AI-generated images, learning how often this is actually possible and whether targeted training can improve the likelihood of these models actually being foldable.
- Fine-tuning existing text-to-image models on images of crease patterns and researching whether we can get them to generate crease patterns which are at least mostly correct (i.e. foldable), and later whether these models can generate CPs for models that resemble given subjects.
- Fine-tuning large language models on origami-related literature to see how much we can improve its knowledge in this domain compared to raw ChatGPT and friends.
- Trying to get large language models to generate origami crease patterns. People have been able to get some basic SVG out of Chat GPT so perhaps with targeted training, it could be made output CPs in SVG or Oripa OPX formats. It might make sense to try developing a shorthand notation for describing folding process more strictly than with free text, perhaps similar to chess notation, and training the AI on models described using such notation. The obvious issue is that all training data would have to be generated from scratch. Update: it seems FoldMation uses a DSL (Domain-Specific Language) for describing the folding process of origami which might be just right for the kind of Machine Learning described above.
- Creating a text-to-stick-model generator. As outlined above, building such a component and combining it with existing origami design tools is practically the only things missing before we can get a crude text-to-crease-pattern system which I expect to be the first actually feasible AI system able to handle the full design path (leading to a foldable base, without shaping, at first).
In these suggestions I focus on fine-tuning existing AI models since building an origami-focused model from scratch seems rather unfeasible right now due to the amount of work and costs involved. The outcome of these ideas is uncertain: they might produce good results or not, but nonetheless this is where I think research should begin. On the other hand, the field of AI has already provided some big surprises such as the success of large language models, so perhaps it will be completely different ideas rather than these that actually allow us to build origami-designing Artificial Intelligence.
Controversies

AI image generators have sparked a lot of controversy, especially in the internet artists’ community. The topic is broad enough to deserve a separate article, so I’ll just list the main points of contention. Critics argue that AI-generated images can be used to easily generate and spread misinformation, that they are prone to propagating various stereotypes, and that the way they are generated misuses actual artists’ work by exploiting it without any compensation or outright plagiarizing it. Finally, the last point might lead to artists losing their jobs and a decline in actual creativity.
First, I think the potential for controversy differs between different applications of AI. I doubt anyone will take issue with a future origami tool which thanks to AI will be able to automatically find a reasonable layer ordering for a complex model folded from CP, just as few in the computer graphics world have objected to the use of smart artifact removal filters. The point where lots of discussions arise is when the AI becomes able to take over the design role.
These discussions are bound to pop up in the origami community as well, and actually already have. However, I think only the last issues, those related to AI’s influence on art and artists, will be relevant to the world of origami. In contrast to e.g. graphic designers, origami creators rarely make a living out of their art. While there are clear uses for mass-producing various images, and thus demand for ways to automate such tasks rather than having people do them, I don’t see any real-world uses for mass-designing origami models, and thus little incentive to do so other than for fun. Thus, I think the economic aspects of AI being able to take over designers’ role, are much less pronounced in the origami community than in communities working with other media.
There remains of course the issue of “anyone can create in minutes a design I as human designer have needed years of experience to be able to make”. As long as AI-based work is not passed off as being designed manually, I don’t think this is going to be a big issue. People still train running and cycling despite there being cars, and there are both running races and car races. I think that due to not being much commercialized, and many people doing it just for the fun of it, origami is in the lucky position to be largely spared from the controversies that have become much more serious issues elsewhere. Where there is no incentive to mass-produce, the ability to do so matters little.
I also believe that origami community has so far proven to be quite tolerant when it comes to people working in different ways. There are, of course, discussions on what is origami and what is not, but I don’t see any holy wars over someone using a particular technique while someone else rejects it. Designers in the field of supercomplex origami already use advanced computer tools, and people designing minimalistic wet-folded models who don’t use them simply don’t care. I don’t think adding AI able to design a model from start to finish to the toolbox would change this attitude much. Origami is to a large degree about self-imposed arbitrary bounds1, such as not using cuts and glue. Many things could be easier built even today with additional tools, which we consciously choose to not use. AI design will be just one more such tool which some creators will use while others will not.
On the other hand, the “AI is just plagiarism” argument could be better grounded for origami than for other media. The way these systems learn based on examples and how their outputs relate to training data is complex, and I believe the issue is not quite so clear-cut. However, for origami the training sets are going to be much smaller than for photographic or artwork-based images due to fewer examples being available globally. Thus, the probability of generating works whose large portions are copied verbatim from training data is probably going to be higher. Whether that actually happens remains to be seen.
Why this might all never happen

The fact something is technically possible does not mean it will actually happen.
Most often, the cause is economics: some things are possible but very costly. As of 2023, the last time people have walked on the Moon was 50 years ago, in 1972, and despite it clearly being possible, the next attempt is not planned until 2025. Moon landings were not economically grounded, but they were backed by strong political will and would not have happened without it.
Another cause may be social: people or institutions rejecting an approach on various grounds.
Generative AI in the form of text-to-image systems has both direct practical uses (creating artwork for websites and other media) and is a great testbed that companies can use to showcase their capabilities. The same is true for large language models such as ChatGPT. This drives development and allows companies to invest considerable resources into building and refining such systems.
Origami, on the other hand, lacks such economic incentives. Few people make money off it, and few enough people understand it to make origami AI a good demo of a company’s capabilities. Therefore, I expect any origami-specific developments to come either out of academia or to be created by a dedicated hobbyist. Despite being a niche, computational origami is a thing, and there are some researchers working on it. Should, for example, a dedicated PhD student find interest in both AI and origami, they could probably single-handedly kick-start this whole area of research. Commoditization may provide another venue. If AI technology becomes very ubiquitous, cheap and simple to use, applying it to a new domain may not require any expertise anymore. Such commoditized technology will not be cutting-edge, but tommorow’s legacy tech will likely be ahead of today’s cutting-edge anyway.
Another reason which might make development of origami AI difficult could be the lack of training data. Machine Learning usually relies on large numbers of examples. Stable Diffusion was trained on 2 billion images, and this scale was only possible because of scraping captioned images from the web, previously created for other purposes (which has in itself caused some controversy). There isn’t that much origami-specific data, even of simple images of folded models, much less so crease patterns with proper descriptions. All is not lost since fine-tuning existing models is often possible with much fewer images, sometimes even just several, but it remains to be seen how far we can get using this approach.
Summary
I argue that while computer software which can do high-quality, end-to-end origami design on a variety of subjects and using a variety of styles is still quite far away, a rudimentary system taking a textual description and outputting a foldable crease pattern for a limited range of subjects, is likely possible even with today’s technology. This post outlines a roadmap for building such a solution using existing tools and suggests further steps needed to improve it. However, I also point out why despite being technically possible, many AI-based tools for origami may not materialize any time soon. At the same time, I argue that various controversies which shook the visual arts world upon the arrival of high-quality generative AI models, are likely to be weaker in the origami community.
Making predictions is hard, especially in a new and very active field, so it will be interesting to come back to this article in a few years and see how well it has aged.
-
Thanks to Hans Dybkjær for an inspiring e-mail exchange, originally sparked by a discussion of origami classification but which I think is relevant to the subject of AI in origami as well ↩
Comments