How Good is DALL-E Mini at Origami?
Lots of people have recently been posting results of their experiments with DALL-E, an AI model that can generate images based on text prompts. Just for fun, I decided to check what its idea of origami was. Since access to the full model, as well as its most recent incarnation, DALL-E 2, is limited, I tested using a similar, but much simpler DALL-E Mini model, which is freely available.

To start with something simple, the first prompt I tried was “origami crane on a table”. I was a bit disappointed, since, the crane being a popular model, I expected the images to resemble the crane quite closely (the “on a table” part worked better). While the generated objects do have some origami-like quality, they are rather far from resembling actual cranes, though the last image comes closest.
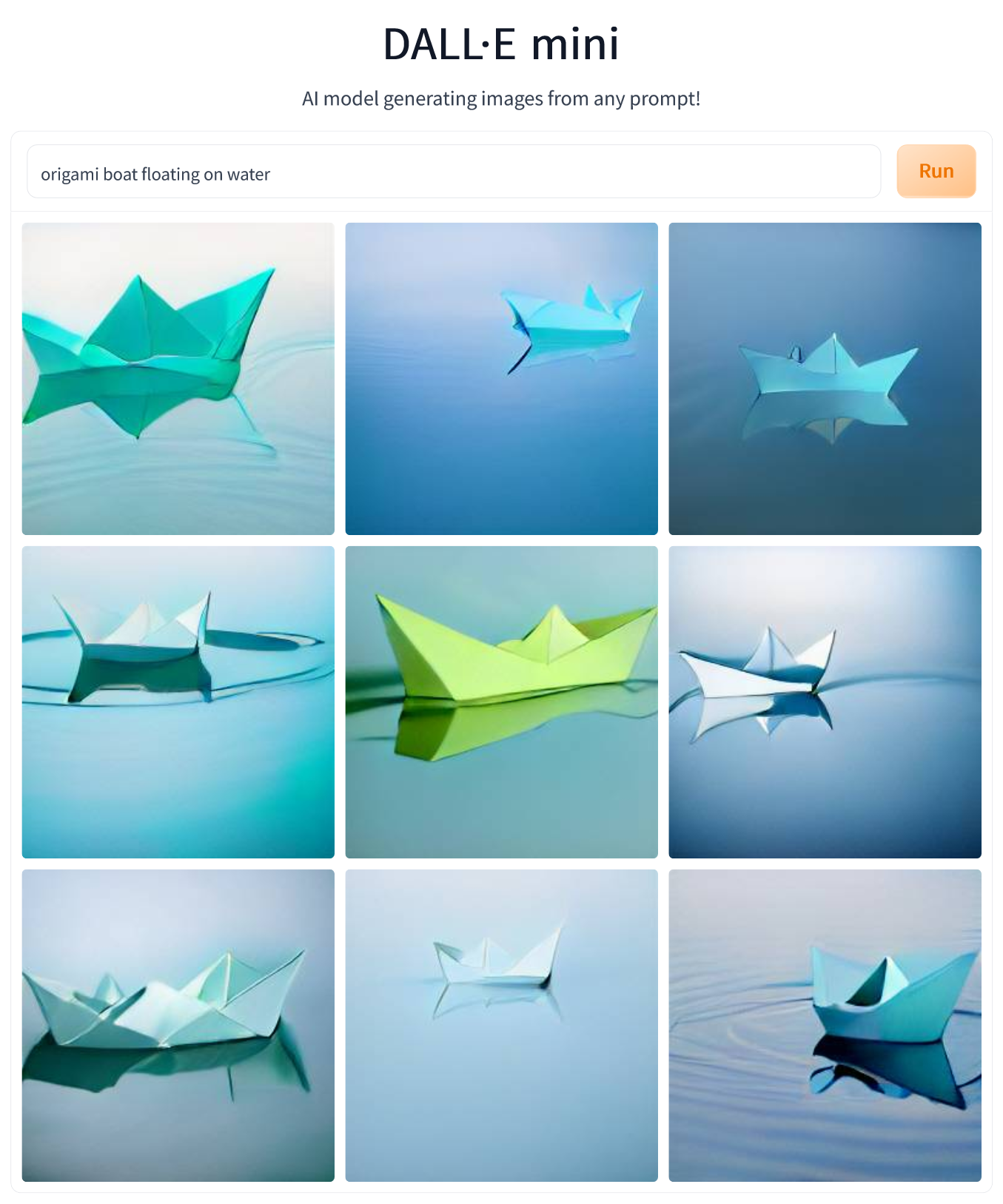
Another popular model is the paper boat, so “origami boat floating on water” was another prompt I checked. This one worked much better, with all generated images coming quite close to what I expected, and some (e.g. #6, #8, and #9) being really good, with the boat, water, and reflections all in the right places. My guess why the boat worked out so much better than the crane is that it boils down to the learning data. Possibly, paper boats are much more prevalent in stock images or other input data than origami cranes.
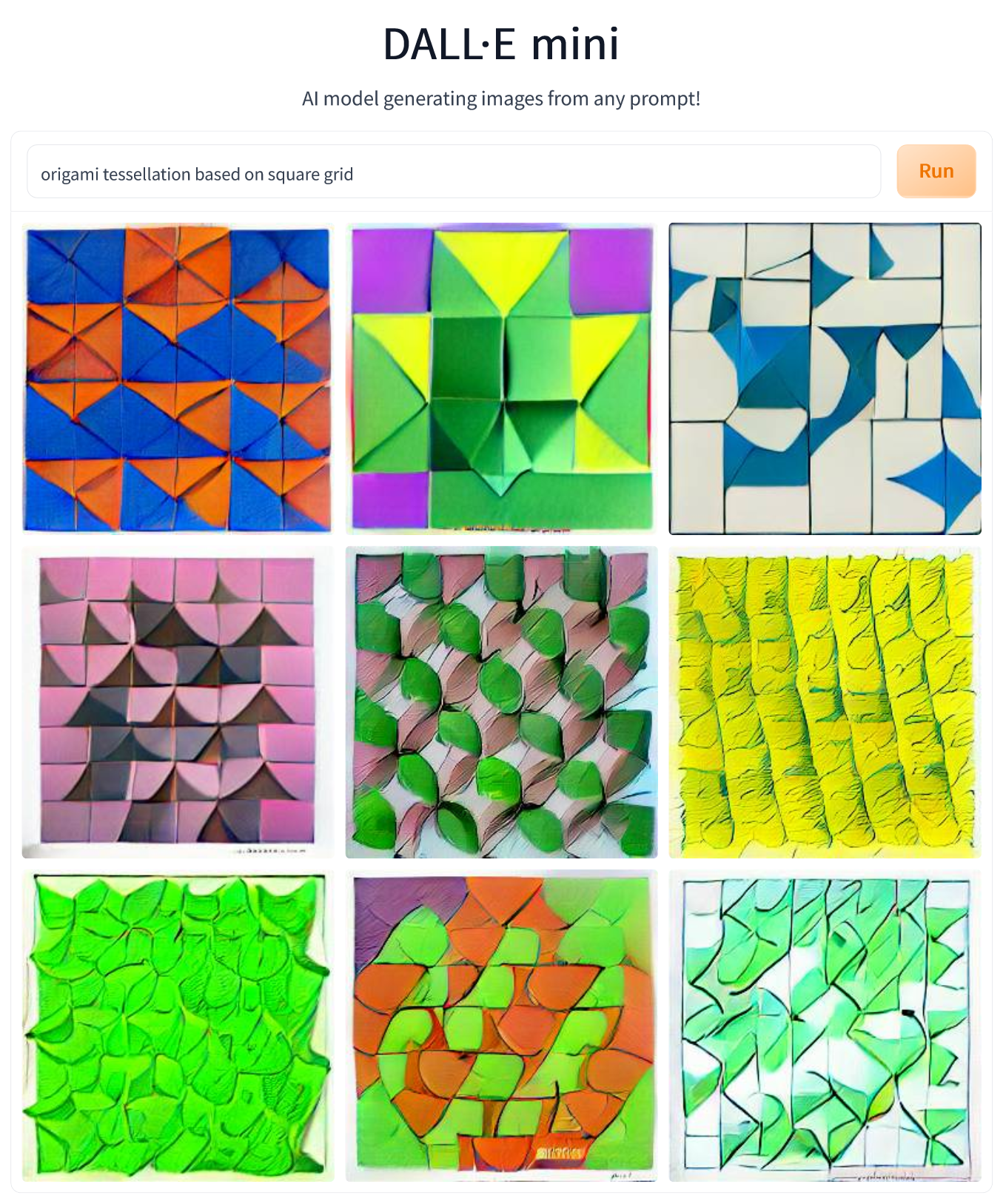
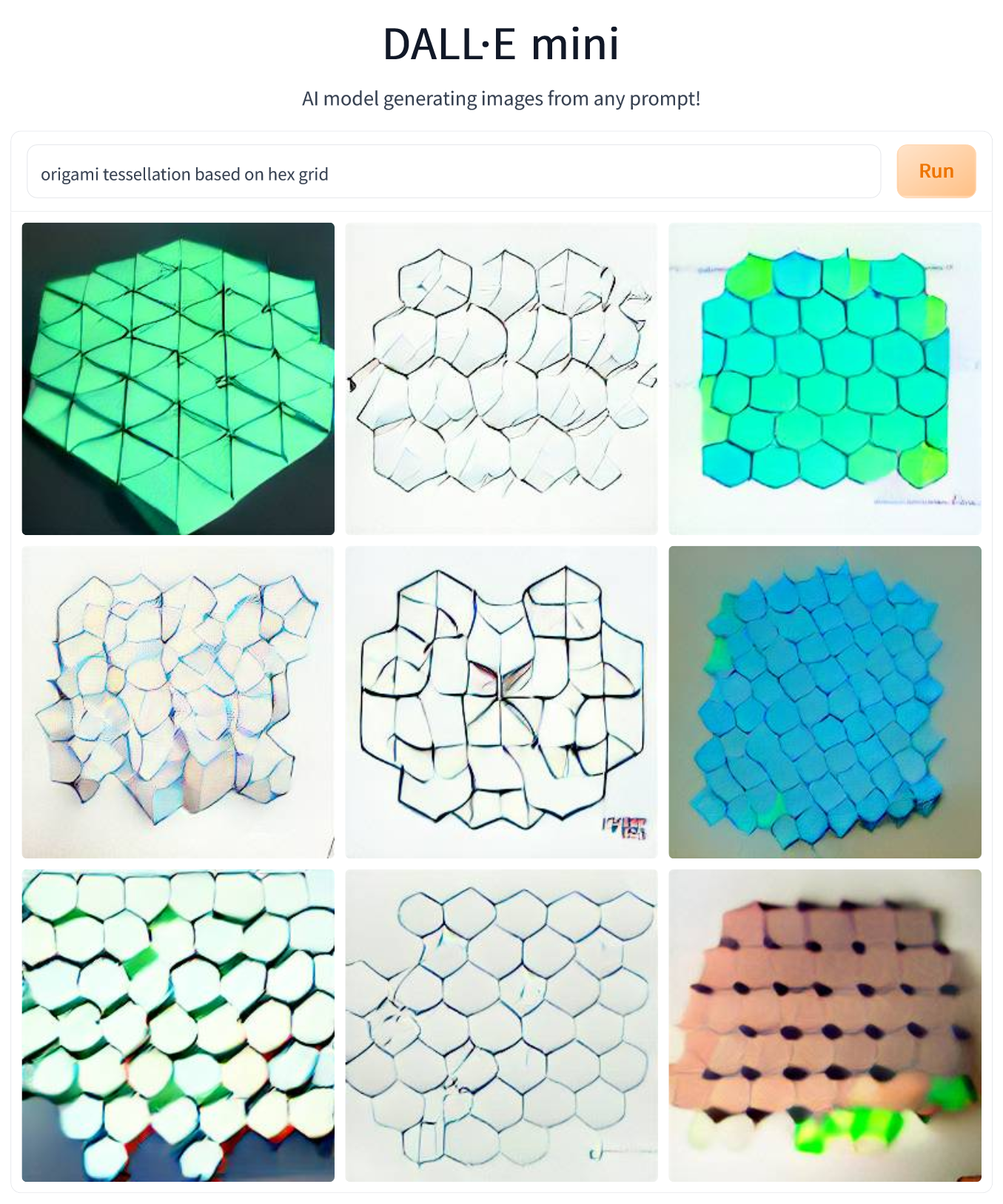
The type of origami I fold most are origami tessellations, so I prompted DALL-E Mini to generate an “origami tessellation based on square grid” and an “origami tessellation based on hex grid”. The results were… interesting. What the model got right in both cases was the idea of tessellations being repetitive patterns. It also interpreted the words square and hex as referring to the pattern’s symmetry. Unfortunately, in the case of hex grid, it took things too literally, with many of the generated patterns containing literal hexagons (which happens, but is usually not the case). Also, in both cases, the patterns do not look too much like origami and rather resemble abstract paintings (especially those square-grid based). My blind guess about what’s happening is that the system is aware of the notion of a tessellation (understood in the mathematical sense), and of origami being a kind of style, but is not aware of what origami tessellations are, and thus my prompts caused it to generate “tessellations, styled as origami” rather than actual “origami tessellations”. Again, a matter of training data, probably.

Another common genre of geometric origami, “modular origami polyhedron”, generated surprisingly good images. They are all blotchy and not too detailed, but they all have the right shape and basic features. Interestingly, they all also display multiple colors, a feature common, but not required, for actual models of this type.
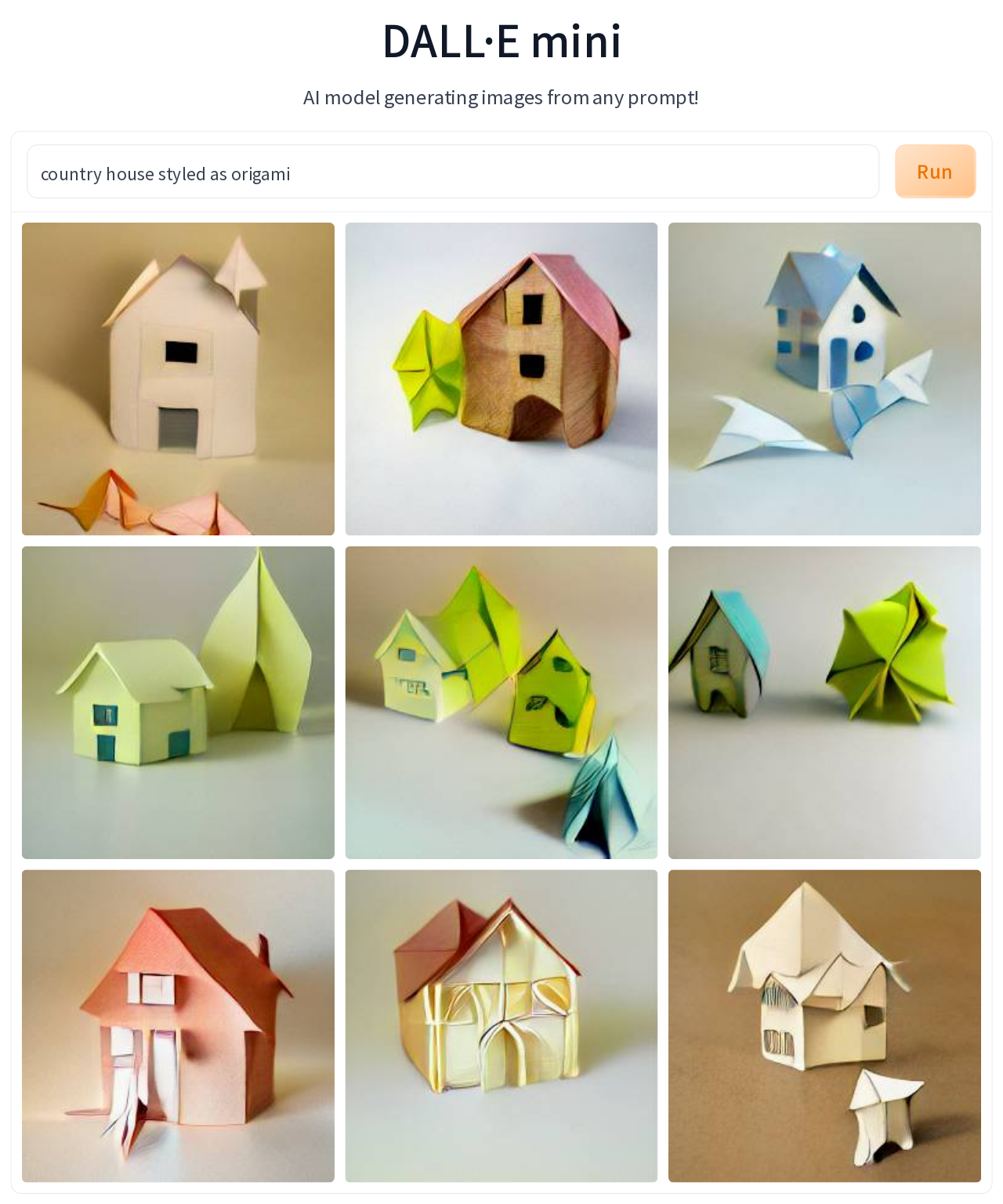
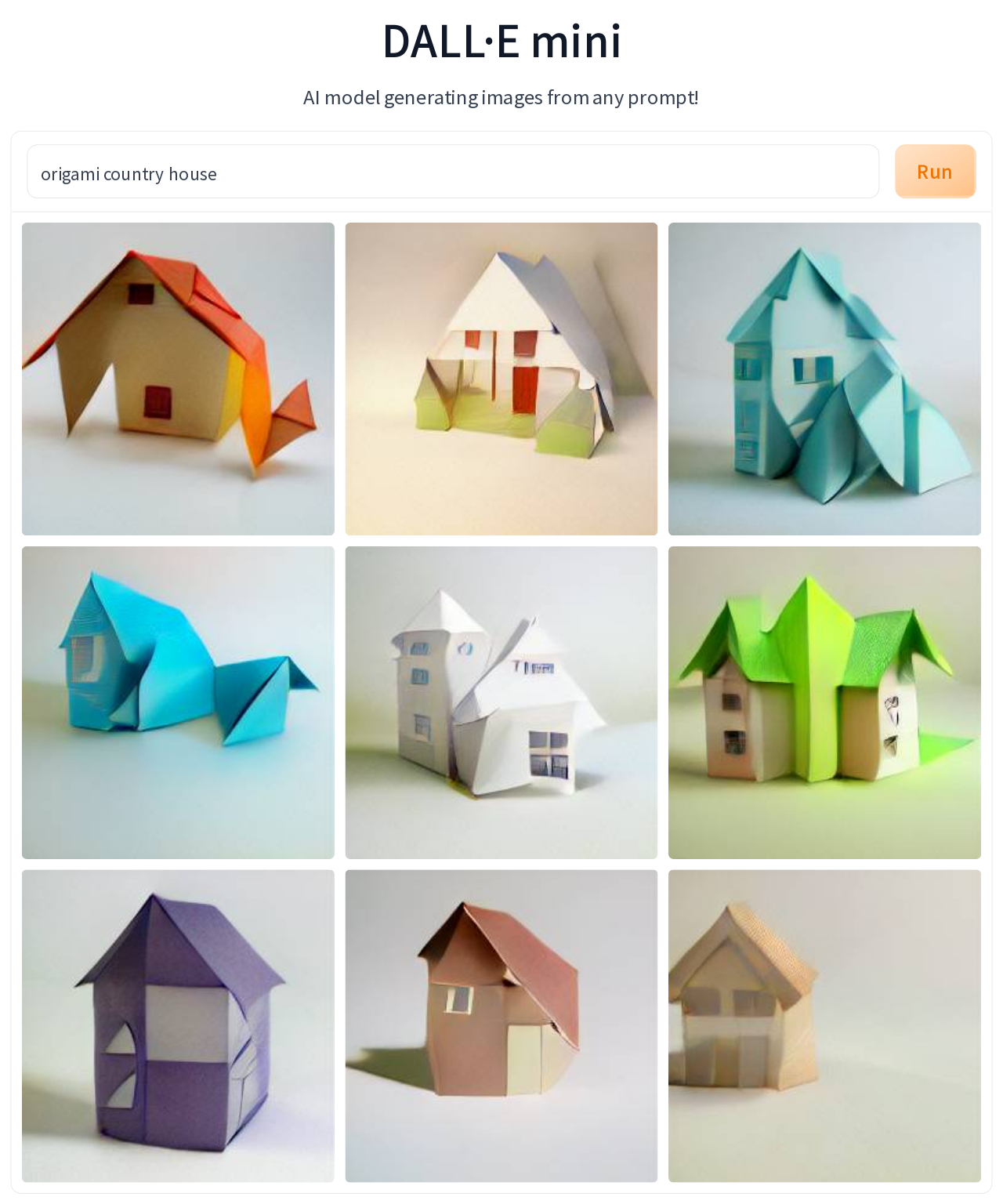
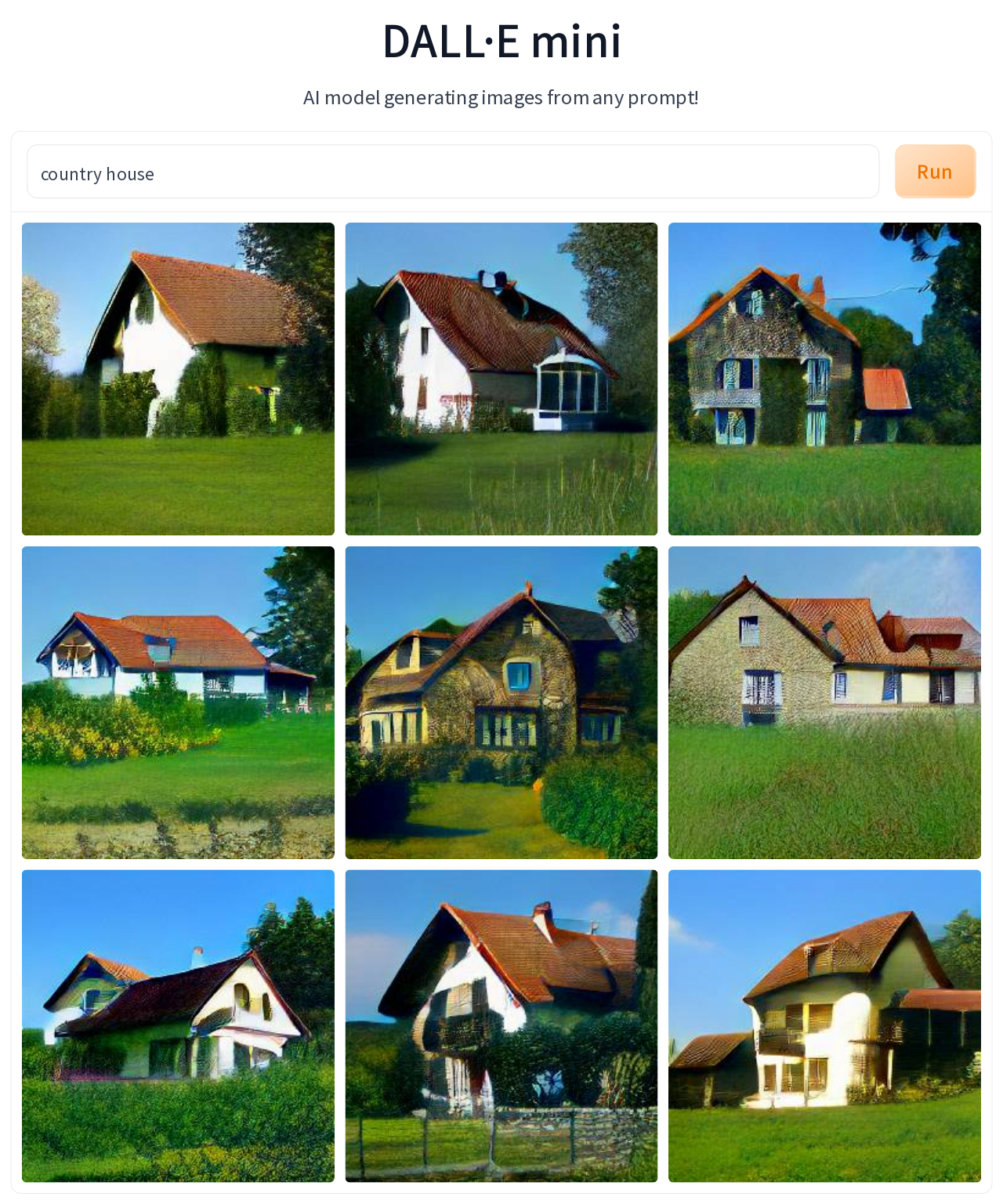
To check my hunch that for DALL-E Mini in most cases being origami is more about style transfer than referencing actual origami models, I tried several prompts that used the phrase “styled as origami”. You can see example results for “country house styled as origami”, and compare them to what is generated for “origami country house”. Essentially, results are the same (give or take the random variation visible also for images created in response to a single prompt). In both cases, the results look pretty good and bear some origami styling (I found the thick pleat sections in image #8 for first prompt interesting), but in no way do they resemble actual origami models of houses. Just for comparison, below I added the results for the prompt “country house” without any mentions of origami.
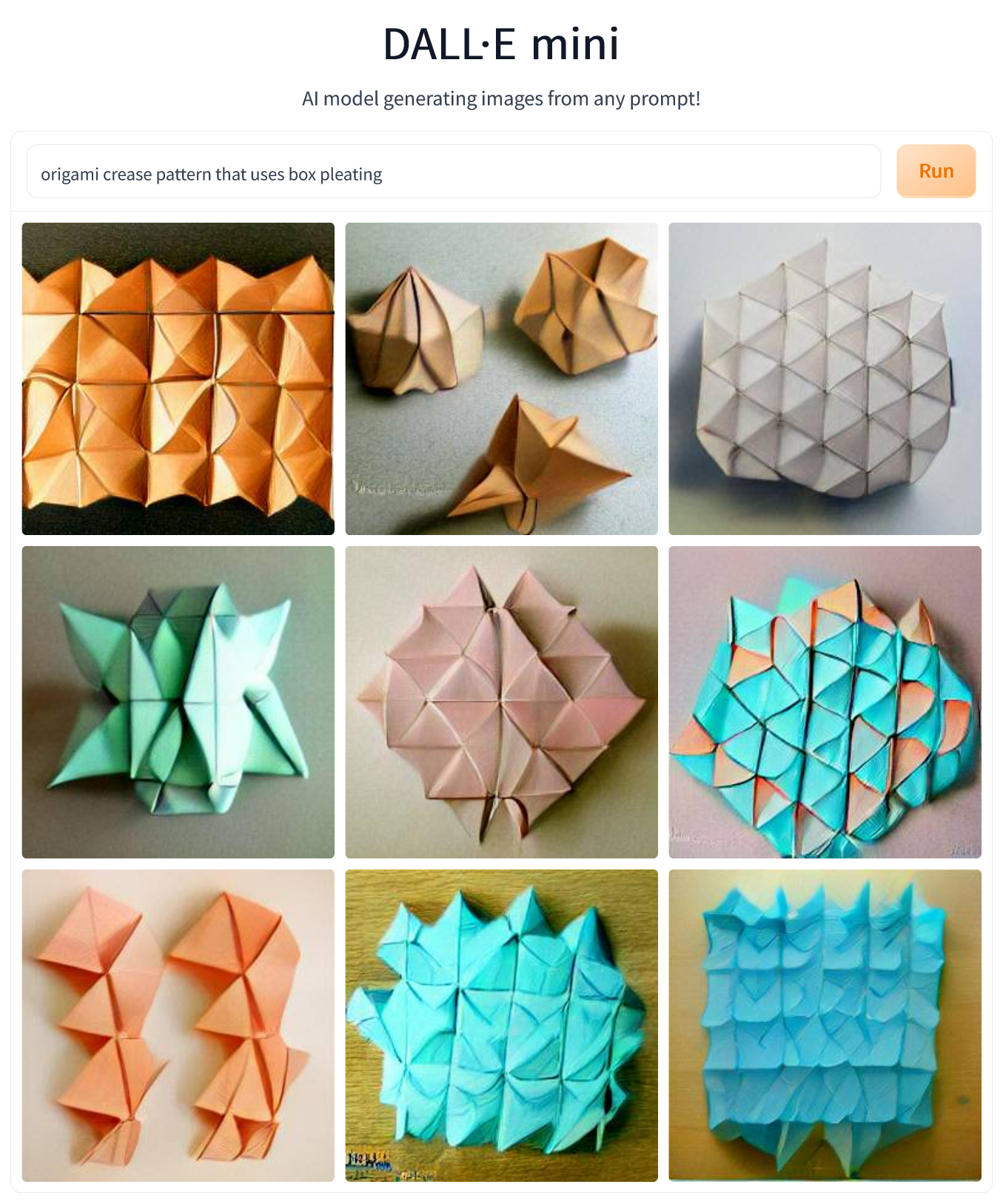
How about origami instructions? I started with the rather ambitious “origami crease pattern that uses box pleating” which resulted in a complete disaster. None of the images come even close to what they should be like. Some indicate that the model interpreted the prompt literally as a bag of words since e.g. image #2 contains objects that could well be boxes, styled as origami in a manner similar to that seen in some previous images.
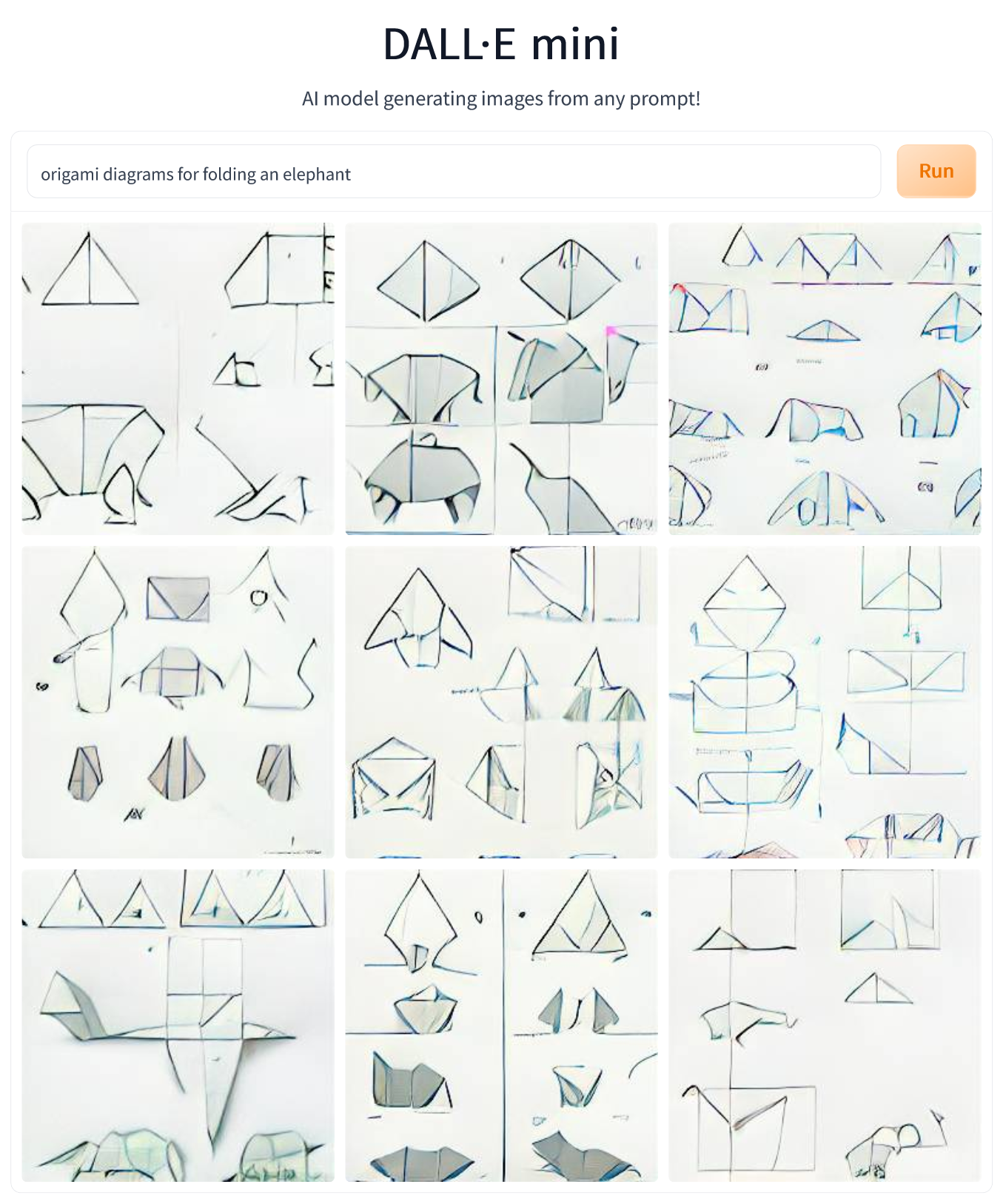
Crease Patterns are hard to grasp even for many humans, so I decided to see what DALL-E Mini thinks of traditional step-by-step diagrams. Given the prompt “origami diagrams for folding an elephant”, it generated drawings which, even though they make no sense as instructions, actually mimic the general style of origami diagrams quite well. All generated images show the typical layout of multiple diagrams on a single page, and some show shapes that resemble an elephant. Obviously, there is no logical progression of folding between the steps, since the model does not know the steps represent a sequence. This is probably an issue similar to the one which causes DALL-E to not be very good at generating text even though it can deal with individual letters quite well. And obviously, typesetting a word from letters is much easier than finding a sensible order of folding diagrams.

So, overall, how good is DALL-E Mini at origami? Not very good, but it fails in interesting ways. It seems to have learned what an origami boat is, and that it looks quite different from a regular boat, and grasps modular origami polyhedra, and possibly origami dragons, but for other subjects I tried, it treats the word origami in the prompt only as a styling hint. It can not draw crease patterns, but standard origami diagrams it generated looked quite good, though they were gibberish from a semantic point of view.
Several things would be worth exploring as a next step. First, it would be very interesting if anyone with access to DALL-E 2 or Imagen, could check the same prompts. DALL-E Mini is not state of the art anymore. But, since what the model outputs depends on learning data, what makes me most curious is what these models could generate if they were fed a dataset focused on actual origami.
Update: For comparison, here are some results generated for the same prompts but using DALL-E 2 (thanks to Harish Garg) and crane and dragon, also using DALL-E 2 (thanks to Christopher Drum). The improvement from DALL-E Mini is impressive.
Comments